摘要:设计了一个嵌入式语音识别系统,该系统硬件平台以ADSP-BF531为核心,采用离散隐马尔可夫模型(DHMM)检测和识别算法完成了对非特定人的孤立词语音识别。试验结果表明,该系统对非特定人短词汇的综合识别率在90%以上。该系统具有小型、高速、可靠以及扩展性好等特点;可应用于许多特定场合,有很好的市场前景。文中讲述了该系统CODEC、片外RAM、ROM以及CPLD等与DSP的接口设计,语音识别运用的矢量量化、Mel倒谱参数、Viterbi等有关算法及其实际应用效果。
关键词:ADSP-BF531;语音识别;离散隐马尔可夫模型;非特定人;孤立词
自上世纪70年代以来,国内外的专家们在语音识别研究领域内取得了重大突破,先后出现了动态时间规整技术(DTW)、隐马尔可夫模型(HMM)和人工神经网络(ANN)等3种主要方法。DTW虽然在孤立词语音识别中取得了不错的性能,但其要求的存储量和计算量太大;ANN虽然前景看好但其目前尚未有突破性进展,目前它们都难以在工程中得到广泛的应用。HMM算法使语音识别的计算量得到大大减少,而且正确率较高,从而在语音识别中得到广泛引用。
笔者在以ADSP-BF531为核心构建的嵌入式系统上实现了对非特定人、孤立词的语音识别,该系统采用了端点检测、矢量量化(VQ)和离散隐马尔可夫模型(DHMM)等算法。
1 ADSP-BF531介绍
ADSP-BF531是ADI公司Blackfin系列的高性能DSP,其最高主频为400MHz,内有2个16位MAC,2个40位ALU,4个8位视频ALU,以及1个40位移位器,RISC式寄存器和指令模型,编程简单,编译环境友好。
BF531包含丰富的外设,通用外设如UART、带有PWM(脉冲宽度调制)和脉冲测量能力的定时器、通用的I/O标志引脚、以及一个实时时钟和一个“看门狗”定时器。它还有多个独立的DMA控制器,能够以最小的处理器内核开销完成自动的数据传输。DMA传输可以发生在ADSP-BF531处理器的内部存储器和任何有DMA能力的外设之间。此外,DMA传输也可以在任何有DMA能力的外设和已连接到外部存储器接口的外部设备之间完成(包括SDRAM控制器、异步存储器控制器)。具有DMA传输能力的外设包括SPORTS、SPI端口、UART和PPI端口。每个独立的有DMA能力的外设至少有一个专用DMA通道。
2 硬件电路设计
该系统电路主要由DSP、音频编码器、CPLD、片外SDRAM、FLASH和EEPROM存储器以及电源、时钟等组成。硬件接口如图1所示。
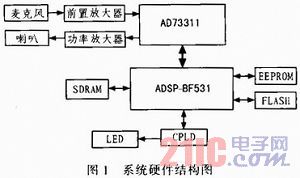
各器件的主要功能如下:
1)AD73311将经前置放大后的麦克风音频信号经A/D转换后通过串行端口输入BF531,同时完成对BF531输出的数字音频信号的D/A转换,而后输出到功放和喇叭;
2)BF531作为该系统的核心,对信号进行特征提取和DHMM识别,同时对其外围的器件进行控制管理;
3)CPLD完成对DSP的外围的器件时序和数据流程控制,以及对LCD显示屏初始化检测设置;
4)由于DSP片内的RAM有限,配置了一块SDRAM用于扩展系统的内存,以满足程序运行时数据和指令存储的要求;
5)EEPROM用于存放DSP程序代码和系统初始化所需的数据;
6)FLASH用于存放训练样本库。
2.1 AD73311与BF531接口设计
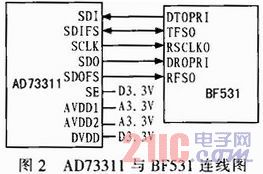
本系统中设计AD73311的采样率为16 kHz,其与BF531的串口0(SPORT0)连接,通过DMA方式在单时钟周期内完成操作。BF531支持32 bit的串口数据传输,由于AD73311为16 bit的音频器件,而且16 bit已可满足系统精度要求,因此本系统只使用了BF531的主传输数据通道,即:DTOPRI和DROPRI,而将第二传输数据通道DTOSEC和DROSEC进行了屏蔽。AD73311与BF531的连接方式如图2所示。
2.2 SDRAM接口设计
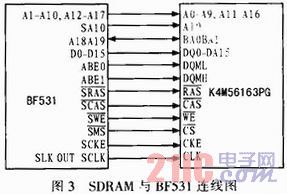
SDRAM主要用于扩展系统内存,为保证程序运行的裕量及后续升级的需要,这里选用了三星电子的一款容量为32 MB的移动式SDRAM,其型号为K4M56163PG。SDRAM与DSP的I/O总线连接,如图3所示。
2.3 EEPROM接口设计
EEPROM主要用于存放程序代码,选用ATMEL公司的AT45DB161D-TU型的EEPROM,该型存储器采用SPI接口,容量为2 MB,可以满足程序存储的要求,其与DSP的SPI端口连接。
通过设置EEPROM存储器的SPI主模式启动(即设置BMODE=11),现实配置BF531为连接一个SPI存储器的主设备和存储器的加载。为了正常工作,该加载模式需要在MISO加上拉电阻。否则,BF531将从MISO引脚读取到0xFF(即SPI存储器没有写任何数据到MISO引脚)。不仅MISO线上的上拉电阻是必要的,额外的上、下拉电阻还有如下2个用途:
1)上拉PF2信号,确保SPI存储器存DSP复位状态下未激活;
2)在SPICLK上用下拉电阻,使显示画图更加清晰。
2.4 FLASH接口设计
片外FLASH主要用于存训练样本库,本系统采用的NANDFLASH为三星电子的K9F8G08U0M-PIB0,该FLASH为工业级SLC架构(Single Laver Cell,单层单元)芯片,具有速度快、可靠性高等特点,而且容量为1 GB,可以满足存储大量样本数据的要求。其采用EBIU(External Bus Interface Unit,外部数据总线)和单个GPIO(General Purpose Input Output,通用输入/输出引脚实现与DSP数据通讯。
3 软件设计
3.1 语音识别(孤立词)的原理
本系统采用的孤立词语音识别的原理框图如图4所示。
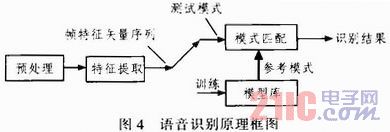
1)预处理 对声源信号进行抗混叠滤波、A/D转换、预加重及端点检测等内容,以获得比较理想的处理信息对象。
2)特征提取 从语音波形中提取出随时间变化的能够反映原始语音特征的矢量序列。
3)语音训练 建立声学模型,将获取的语音特征通过必要学习算法产生。
4)模式匹配 在识别时将输入的语音特征同声学模型进行比较,得到识别结果。
在训练阶段,用户将词汇表中的词依次读一遍,并且将其特征矢量序列存入模板库中。在识别阶段,将输入语音的特征矢量序列依次与模板库中的每一个模板进行形似度比较,相似度最高者作为识别结果输出。
在HHM算法中,语音序列被看做马尔可夫随机过程的输出。假定识别系统的词汇表共包括V个词条,那么在训练阶段需要请很多个说话人分别将这次词条说一遍并存入数据库中。利用这些训练数据可以为每一个词条建立一套HMM参数λv(1≤v≤V)。
在识别时,对于每个待识别语音,可以得到一个观察矢量序列Y=[y1,y2,…yN],其中,N为输入语音所包含的帧数。语音识别的过程就是计算每个HMM模型λv产生Y的概率P(Y|λv),并使得该概率达到最大的HMM模型,那么该模型所对应的词条即为孤立词识别的结果,即:
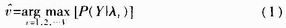
3.2 语音识别算法设计
本系统采用VO/DHMM(矢量量化/离散隐马尔可夫模型)算法,其主要包括预处理、特征提取、语音训练、模式匹配等几个方面。
3.2.1 预处理和特征提取
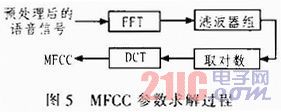
首先采用预加重、汉明窗、双门限法等完成对语音信号的预处理;然后使用Mel倒谱参数(MFCC)进行特征识别,MFCC参数提取的过程如图5所示,其中Mel滤波器组的作用是利用人耳听觉特性对语音信号的幅度平方谱进行平滑。对数操作的用途:压缩语音谱的动态范围;考虑乘性噪声,将频域中的乘性成分转换成加性成分。离散余弦变化主要是用来对不同频段的频谱成份进行解相关处理,使得各维向量之间相互独立。
3.2.2 矢量量化
矢量量化(VQ,Vector Quantization)是一种重要的信号压缩方法,其过程是:将语音信号波形的K个样点的每一帧,或在K个参数的每一参数帧,构成K维空间中的一个矢量,然后对矢量进行量化。量化时,将K维无限空间划分为M个区域边界,然后将输入矢量与这些边界进行比较,并被量化为“距离”最小的区域边界的中心矢量值。
一个VO编码器往往拥有一个或多个由具有代表意义的矢量组成的集合,称为“码本”(本系统中码本大小为256),其中每个矢量称为“码矢量”。在语音识别中,训练用的语音特征通过聚类的方法形成码书;识别时,VO编码器将待识别语音的特征矢量与码书中的每个矢量进行失真测度运算,最小的失真测度所对应的码字的标号代替输入矢量。
3.2.3 HMM模型建立及训练过程
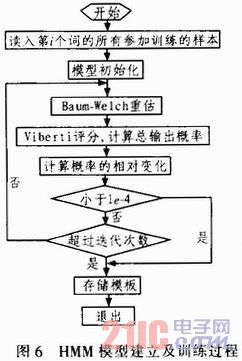
本系统选择尤跨越的从左向有的HMM模型,状态数取6。训练过程中利用Baum-Welch算法和Viterbi算法来计算所有观察序列的输出概率,然后对其进行累加,得到总输出慨率,采用前后2次的输出概率的相对变化小于一定阈值(如:1×10-4)或超过迭代次数作为训练结束的判据。程序流程图如图6所示。
3.2.4 语音识别
语音识别的过程即是用Viterbi算法将经将输入的矢量量化后的语音与模型库中的参考模板进行匹配。
Viterbi算法是一种前向搜索算法,其可以是在给定相应的观察序列时,找出从模型λ中找出的最佳状态序列,即选择输出概率最大的模版作为输出结果。对数形式的Viterbi算法,能够避免大量的乘法运算,减少计算量,同时还可以保证有很高的动态范围,不会出现由于过多的连乘而导致溢出问题,其算法如下:

4 实验结果及分析
系统选取500字的词表,词长不大于5;在进行识别前,对每个待识别的词进行训练,参加训练人数为30,其中男性20人,女性10人。实验选取30个人,其中参加训练和未参加训练的各15人,对简单语音命令、数字串、字母串进行测试(每人反复测试5次),结果如表1所示。
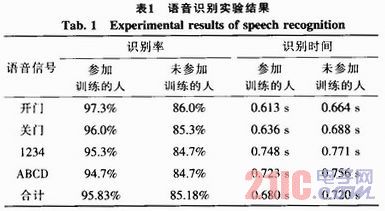
通过以上数据可以看出,该系统的对非特定人(包括参加训练和未参加训练)的简单汉语词汇、数字串、字母串等的综合识别率超过了90%,识别时间在0.7 s左右;具有较高的识别率和较好的实时性。从表中可以看出,未参加训练与参加训练的识别率相差约10%,可以通过在软件中增加训练样本量以及完善有关算法等来进一步提高其识别率。
5 结束语
该嵌入式语音识别系统在以ADSP-BF531为核心的硬件基础上,成功运用DHMM算法完成了对非特定人孤立词的语音识别。该系统运行稳定、可靠,其识别率及实时性均满足使用要求,同时还具有存储容量大、运算速度快的特点,为软件运行留下了充足的裕量,系统后续的完善和升级较容易实现。该系统可应用于许多特定场合,有很好的市场前景。
|


